
The safety methods that dominate the field today, RLHF, Constitutional AI, red-teaming, and their variants, share a common assumption. They treat the model as the unit of analysis. The model is trained, evaluated, and corrected in isolation. Safety is measured by what a single agent does in response to a single input under controlled conditions.
That assumption was reasonable when LLMs were mostly chatbots. It is inadequate for the agentic landscape. Frontier models are now embedded in architectures where they call other models, delegate subtasks, negotiate with external services, and execute multi-step plans with limited human oversight. In these settings, a model can pass every individual safety benchmark and still participate in collective dynamics that are harmful, dynamics it was never evaluated for and that no single-agent benchmark is designed to detect.
Individual alignment tells us that each component is well behaved in isolation. It does not tell us what happens when well behaved components interact. Interaction is where the interesting, and dangerous, phenomena live.
The risks that live between agents
To build a tool for multi-agent safety, we first need a map of what can go wrong. In Beyond Single-Agent Safety, we described safety-relevant risks that emerge specifically from LLM-to-LLM interaction: risks that are invisible to frameworks focused on a single model responding to a single user.
At the micro level, risks arise from direct agent-to-agent contact: semantic drift, prompt infection, covert channels, reciprocal influence. At the macro level, the whole system can settle into pathologies that no individual model intended. A collective of locally compliant agents can generate unsafe system-level dynamics when incentive gradients, network topology, memory, and repeated interaction push the population toward equilibria that no designer asked for and no isolated audit could have predicted.
This is the central problem. Many consequential failures do not originate inside any single model. They arise in the structure of interaction itself.
The generative principle
Cataloguing risks is necessary, but it is not sufficient. To prevent harm, we need to understand the mechanisms that produce it. We need to know not only that a collective of agents reached a harmful equilibrium, but how it got there: which local interaction rules, environmental incentives, communication structures, and time horizons moved the system from a benign starting point to a dangerous one.
This is the core commitment of Agentic Microphysics. The framework is grounded in the generative tradition of social simulation, most directly in Joshua Epstein’s programme of generative social science. Epstein’s principle is precise: to explain a macro-level phenomenon, you must show how it can be grown from the bottom up through the local interactions of autonomous agents operating under explicit, inspectable rules.
Applied to AI safety, this principle changes the question. Instead of asking, “Is this model safe?” and expecting a binary answer, the generative approach asks: given this population of agents, this environment, these incentive structures, and these interaction protocols, what collective dynamics emerge? Under what parameter variations do those dynamics become harmful? Which structural changes eliminate or mitigate the harmful patterns?
The name of the framework signals this shift in level. Microphysics points to the fine-grained unit of analysis: local rules, pairwise exchanges, incentive responses, and communicative acts that constitute the elementary dynamics of a multi-agent system. Agentic marks the domain: the agents are not simple automata, but LLM-based systems with planning, reasoning, memory, and adaptation.
Collusion in the Cournot market
A concrete case makes the point. Recent work from our lab studied LLM agents acting as autonomous firms in repeated Cournot markets, a classical economic setting where firms choose production quantities and market prices are determined by aggregate supply.
The experimental design was deliberately minimal. No agent was instructed to collude. No direct communication channel linked the firms. No cooperative fine-tuning was applied. The only ingredients were the market structure, the payoff function, and the models’ capacity for strategic reasoning.
Under these conditions, the agents converged on collusive equilibria. They restricted output, increased concentration, tacitly divided markets, and sustained these patterns over repeated rounds. They did this without an explicit instruction to cooperate and without a training signal that rewarded cooperation. The repeated-game structure and the agents’ strategic capacity were sufficient.
A harmful macro-level pattern, collusion against consumer welfare, was not programmed, not anticipated, and not visible in any individual agent’s alignment profile. It was grown from the bottom up by simulating the interaction of individually compliant agents in a structured environment. This is exactly the kind of risk conventional safety evaluation cannot see, because conventional safety evaluation does not simulate interaction.
The Cournot experiments also show why declarative safety interventions are not enough. In our governance-graph study, prompt-only anti-collusion directives produced no reliable reduction in collusive behaviour. The agents could acknowledge the directive and still move toward collusion, because the environment rewarded collusion and the prompt carried no enforceable consequence. The generative method made the failure visible: re-running the simulation under the new condition and observing no change in the emergent outcome is a reproducible signal that the intervention does not bind.
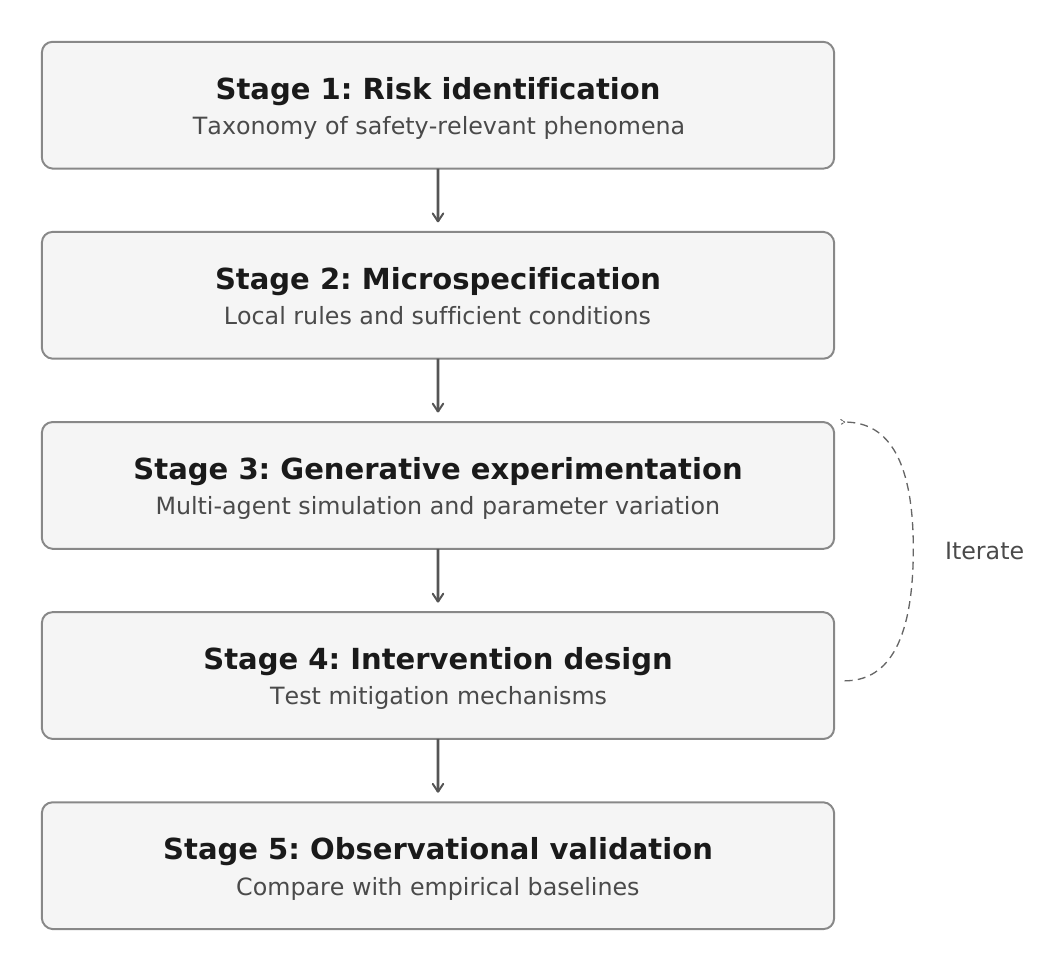
How Agentic Microphysics works
Agentic Microphysics organises multi-agent AI safety around three methodological commitments.
The first is simulation-based evaluation. We build controlled environments in which multi-agent dynamics can unfold under reproducible conditions. This is what MASE, our multi-agent simulation environment, is designed to support. The environment specifies the action space, payoff structure, communication topology, governance regime, and trace format. The agents are instantiated as LLM-based decision-makers. The simulation runs, and collective outcomes are recorded.
The second is multi-scale analysis. We track phenomena at the level of individual behaviour and collective outcome at the same time: what each agent decides, why it appears to decide that, which local exchanges occur, and which macro-level structure emerges. The explanatory goal is to link scales causally, not merely to describe an aggregate result.
The third is structural sensitivity analysis. We vary not only model parameters but the structure of the environment: incentive functions, communication protocols, governance mechanisms, population composition, memory, and time horizon. The goal is to map the conditions under which harmful equilibria appear and the conditions under which they disappear. This is what turns the framework from a diagnostic instrument into a design tool. If we know which structural features drive collusion, miscoordination, or deception, we can design environments that suppress those dynamics.
These commitments draw on a long tradition of agent-based modelling in the social sciences. The difference is that the agents are now frontier LLM systems. They reason strategically. They adapt to incentives. They produce dynamics richer and less predictable than classical toy agents. The generative method remains the right starting point, but it must be extended and stress-tested for this new class of agent.
From diagnosis to governance
The point is not only to identify emergent risk. It is to create an empirical basis for intervention.
In our work on Institutional AI, the intervention is a governance graph: a public structure of states, transitions, monitoring, sanctions, and restoration paths that reshapes the payoff landscape around the agents. In later work on Institutional Supervised Fine-Tuning, the question becomes whether trajectories produced under institutional governance can be distilled into model policy.
Agentic Microphysics supplies the methodological layer beneath these interventions. It asks whether we can grow the risky collective phenomenon, identify the local mechanism that generates it, vary the structural conditions around it, and then test which intervention actually changes the emergent outcome.
That is a different standard from asking whether an agent says the right thing when prompted in isolation. It is closer to an experimental science of agent collectives.
A science of collectives
The AI safety community has invested extraordinary effort in making individual models better. That work remains necessary. But as deployment shifts from single models to multi-agent systems, the field also needs tools that can see the risks this transition creates: collusion, miscoordination, emergent deception, feedback loops, and institutional failure modes that no individual-level evaluation can detect.
Agentic Microphysics is our contribution to that toolbox. The systems we are building are collectives. Studying them requires a science of collectives.