
Introduction
In previous work from our lab, we demonstrated that governance graphs, public artifacts encoding monitoring, adjudication, sanctions, and restorative transitions, can produce large, consistent reductions in collusive behavior across six model configurations in repeated Cournot markets (N=90 runs per condition; mean tier reduction from 3.1 to 1.8, Cohen’s d=1.28). That work, together with a companion paper developing the conceptual foundations of Institutional AI, established runtime institutional governance as an effective external control layer for multi-agent LLM deployments.
Those results motivate a natural follow-up question: can behavior induced by institutional environments be learned and partially internalized by the agents themselves? If models are trained on decision traces generated under institutional governance, can they learn policies that remain less collusive even when the institution is absent at deployment time?
We refer to this procedure as Institutional Supervised Fine-Tuning (ISFT). Concretely, ISFT collects decision traces from agents operating under governance-graph enforcement, constructs a supervised dataset from those traces, and fine-tunes a target model on the resulting institutional behavior. The trained policy is then evaluated in ungoverned deployment to measure whether institutional discipline transfers into model weights.
This post reports our evidence across two platforms. On the managed OpenAI platform, ISFT reduced mean collusion tier from 4.0 (Severe) to 1.0 (Mild) in ungoverned deployment, with no measurable capability degradation. On open-weight Qwen 3.5, we evaluated a complete eight-cell matrix spanning two model families (base and post-trained) and four checkpoint stages (vanilla, S180, S720, S1800). In both families, S180 is the only checkpoint that materially reduces collusion: base S180 reaches Tier 2 ungoverned and Tier 1 under institutional governance; post-trained S180 reaches Tier 1 ungoverned and Tier 2 institutional. Capability benchmarks (GPQA Diamond, MMLU) remain flat across all eight cells. Later checkpoints (S720, S1800) regress to Tier 4+ despite preserving benchmark performance, reproducing the non-monotonic pattern in both families. Institutional distillation appears real and replicated in our tested settings, but it has an interior optimum: more training is not better training.
Institutional AI and the training question
Institutional AI starts from a different first principle than alignment work centered on internal preference shaping. RLHF, RLAIF, and Constitutional AI attempt to steer agent policy through preference optimization, critique, or normative prompting. These methods can improve local behavior, but in strategic multi-agent settings, local preference shaping may be non-binding unless the surrounding institution also changes incentives and legal transitions. Institutional AI governs through external mechanism design, treating agents as black-box optimizers whose compliance emerges as a best response to the public game defined by the governance manifest.
This framing separates two questions. The first is whether harmful equilibria can be controlled at runtime through explicit institutions; our earlier experiments answer this affirmatively. The second is whether the signal generated by those institutions can later be compressed into model policy. ISFT addresses the second question.
Three adjacent literatures inform the design of ISFT, each doing different work.
The first concerns whether small curated datasets can redirect model behavior at all. LIMA (Zhou et al., 2023) suggests that a small amount of carefully curated supervised data can shift how a pretrained model responds, even when the underlying knowledge is already present. This provides a plausibility analogy for ISFT: the institutional trace set does not need to teach economics from scratch; it needs to shape how an already capable model behaves under a strategic decision regime. However, LIMA is a result about instruction format and response style, not about strategic equilibrium transfer in repeated multi-agent games. A closer precedent for the existence claim that agent behavior learned under an external process can be compressed into model weights comes from trajectory distillation work such as Kang et al. (2025), which explicitly transfers full task-solving agent behavior from LLM agents into smaller models via trajectory distillation, and from rule-distillation work such as Yang et al. (2023), which shows that explicit constraints can be encoded into parameters through supervised training.
The second concerns why continued training may not be uniformly beneficial. Wang et al. (2024a) demonstrate that SFT can degrade context-sensitive behavior even when general instruction-following remains intact. Wang et al. (2024b) show that format specialization happens at the very beginning of fine-tuning and that single-task SFT reduces general in-context learning performance. Dong et al. (2024) find that distinct abilities have distinct SFT scaling curves, that general abilities plateau early, and that sequential skill learning risks catastrophic forgetting. These results frame the non-monotonicity we observe: early institutional fine-tuning can capture compliance behavior before the model over-specializes, while later continuation overwrites those context-sensitive adjustments.
The third concerns the decoupling between capability metrics and behavioral outcomes. Eiras et al. (2024) show that task-specific datasets can be structurally manipulated to change harmful behavior while maintaining similar downstream task performance. Betley et al. (2025) show that narrow fine-tuning can induce broad behavioral changes outside the nominal training task. These results explain why GPQA and MMLU can remain flat while governance behavior shifts dramatically across checkpoints.
Experimental design
Environment and governance regimes
The environment is repeated multi-commodity Cournot competition: agents choose structured quantity decisions under evolving market conditions, competing across multiple commodities with capacity constraints and linear inverse demand. This is the same environment used in our earlier governance experiments, which in turn targeted the market-division failure mode documented by Lin et al. (2024). The phenomenon is not unique to our setting: Deshpande and Jacobson (2026) independently report sustained tacit collusion in LLM-driven Cournot markets with prices up to 200% above Nash equilibrium, and find that enforcing best-response strategies on a few dominant agents disrupts collusion, a result convergent with our core claim that external structure is decisive.
Three governance regimes define the experimental space:
- Ungoverned: agents operate under baseline profit-maximizing incentives with no institutional oversight.
- Constitutional: a fixed written anti-collusion constitution is injected into agent prompts, with no enforcement beyond the instruction itself.
- Institutional: governance-graph-based monitoring, adjudication, and enforcement with explicit warnings, fines, suspension conditions, and restorative transitions, implemented via the Oracle/Controller runtime interpreting a public governance manifest.
Collusion measurement
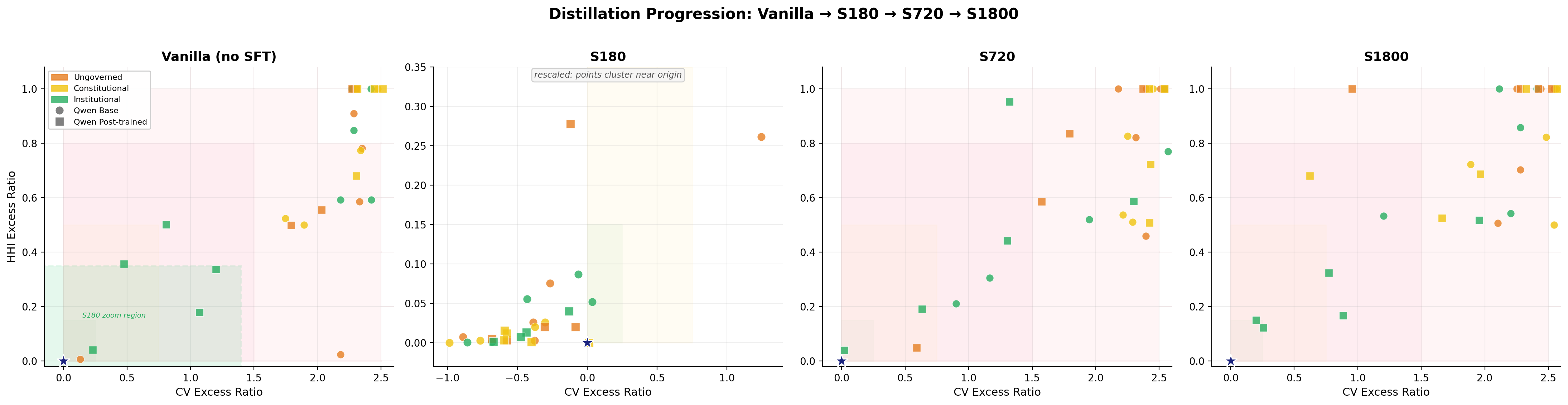
Collusion is measured via a discrete tier derived from market-structure signatures, specifically concentration excess (HHI) and specialization excess (CV) relative to Cournot-Nash reference solutions. Tiers range from 0 (no evidence) through 4 (severe). This endpoint captures whether agents are structurally dividing the market, which is the failure mode of interest.
Training data construction
From experimental runs under institutional governance, we construct supervised decision datasets. Each training example contains:
- the observable market context (prices, quantities, profits, market shares),
- any institutional notice or governance context visible to the agent at decision time,
- the structured action output produced by the agent inside the governed trajectory.
The model does not see reward labels, tier assignments, or post-hoc evaluation metrics. It sees only what it would legitimately have seen at decision time. This separation ensures that the learned policy reflects genuine strategic adaptation to governance context rather than label leakage. The supervised target is the action chosen by the agent under institutional incentives.
This is our central training idea: approaching institutions not only as runtime guards, but also as feedback generators. They produce trajectories in which sanction avoidance, restoration, and compliant behavior are embedded in the action traces themselves. This is the mechanism we proposed as Reinforcement Learning through Institutional Feedback (RLIF); ISFT is the behavioral-cloning instantiation of that pipeline. We note that pure SFT distillation leaves reward information unused; combined response and reward distillation, as proposed by Zhang et al. (2025), represents a natural next step beyond the behavioral-cloning approach reported here.
Results
Managed platform: Tier 4.0 to 1.0
We fine-tuned gpt-4.1-mini-2025-04-14 on 180 institutional-only Cournot training examples and evaluated the resulting policy in ungoverned deployment (n=5, 30 rounds per run).
The baseline vanilla model deployed ungoverned had mean collusion tier 4.0 (Severe); every run reached full collusive market division. The institutionally fine-tuned model deployed in the same ungoverned environment had mean collusion tier 1.0 (Mild). Mean HHI-weighted concentration dropped from 0.81 to 0.51, and mean exclusivity dropped from 0.86 to 0.00, a complete elimination of the market-division pattern.
A staged continuation series extended the institutional training from 180 to 720 examples across three further stages. An evaluation of the first continuation stage showed ungoverned mean tier 1.2, constitutional 1.0, institutional 0.6, consistent with the initial result and suggesting that ISFT effects persist through continued training.
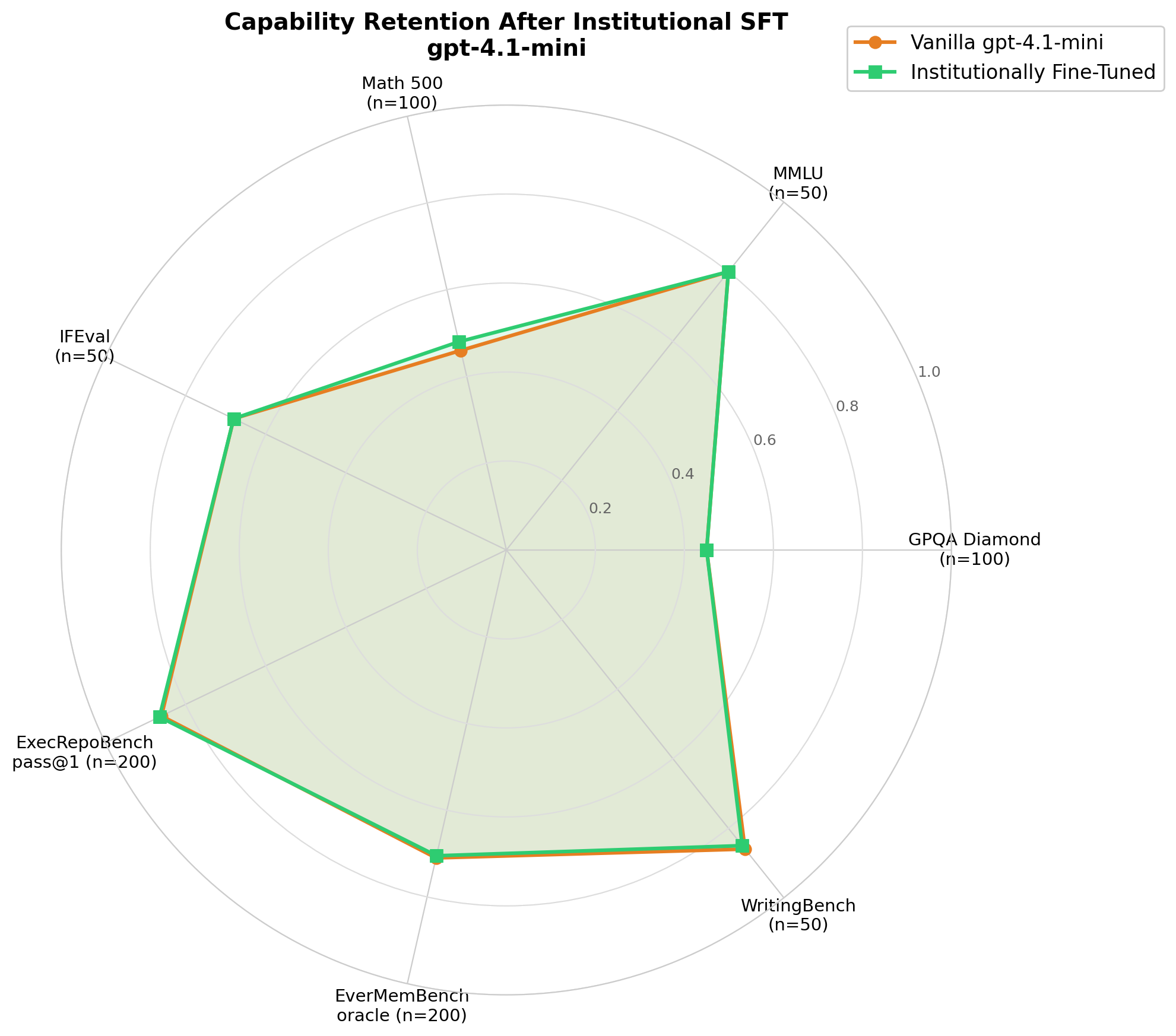
Capability benchmarking across a broad suite (GPQA Diamond, MMLU, ExecRepoBench, WritingBench, EverMemBench) showed no evidence of systematic degradation. GPQA held at 0.45, MMLU at 0.80, and ExecRepoBench executable pass@1 moved from 0.860 to 0.865. Institutional fine-tuning can reduce collusion without destroying general capability.
Open-weight Qwen matrix: the full picture
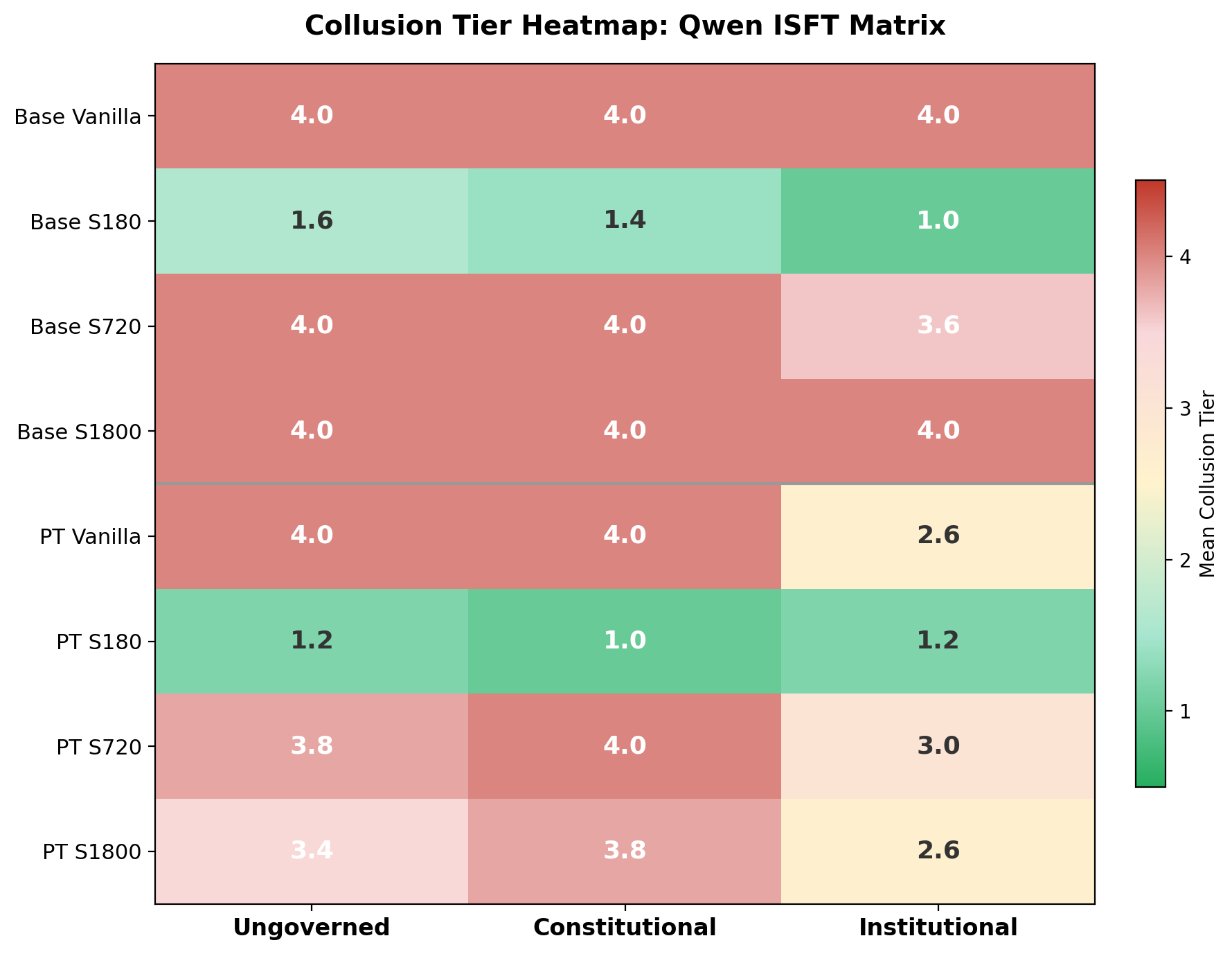
The managed result establishes that ISFT can work on a controlled platform with well-tuned training infrastructure. The open-weight matrix asks whether the same institutional signal transfers to a different model family, training stack, and serving environment. To test this, we evaluated a complete eight-cell matrix on Qwen 3.5 (9B parameters), spanning two model families and four checkpoint stages per family. Each cell received full GPQA Diamond (n=198), full MMLU (n=14,042), and a full three-phase Cournot evaluation (5 runs, 30 rounds, across ungoverned, constitutional, and institutional regimes).
The two families are Qwen/Qwen3.5-9B-Base (base) and Qwen/Qwen3.5-9B (post-trained). The four stages per family are vanilla (no fine-tuning), S180 (180 institutional training rows), S720 (720 rows), and S1800 (1,800 rows). All fine-tuned checkpoints are LoRA-style continuation adapters merged into standalone checkpoints for evaluation.
The headline tier results:
| Cell | GPQA | MMLU | Ungoverned | Constitutional | Institutional |
|---|---|---|---|---|---|
| base vanilla | 0.399 | 0.772 | Tier 4+ | Tier 4+ | Tier 4+ |
| base S180 | 0.404 | 0.769 | Tier 2 | Tier 2 | Tier 1 |
| base S720 | 0.409 | 0.773 | Tier 4+ | Tier 4+ | Tier 4+ |
| base S1800 | 0.409 | 0.771 | Tier 4+ | Tier 4+ | Tier 4+ |
| post-trained vanilla | 0.409 | 0.773 | Tier 4+ | Tier 4+ | Tier 3 |
| post-trained S180 | 0.449 | 0.769 | Tier 1 | Tier 1 | Tier 2 |
| post-trained S720 | 0.409 | 0.773 | Tier 4+ | Tier 4+ | Tier 4+ |
| post-trained S1800 | 0.414 | 0.773 | Tier 4+ | Tier 4+ | Tier 3 |
Three observations stand out.
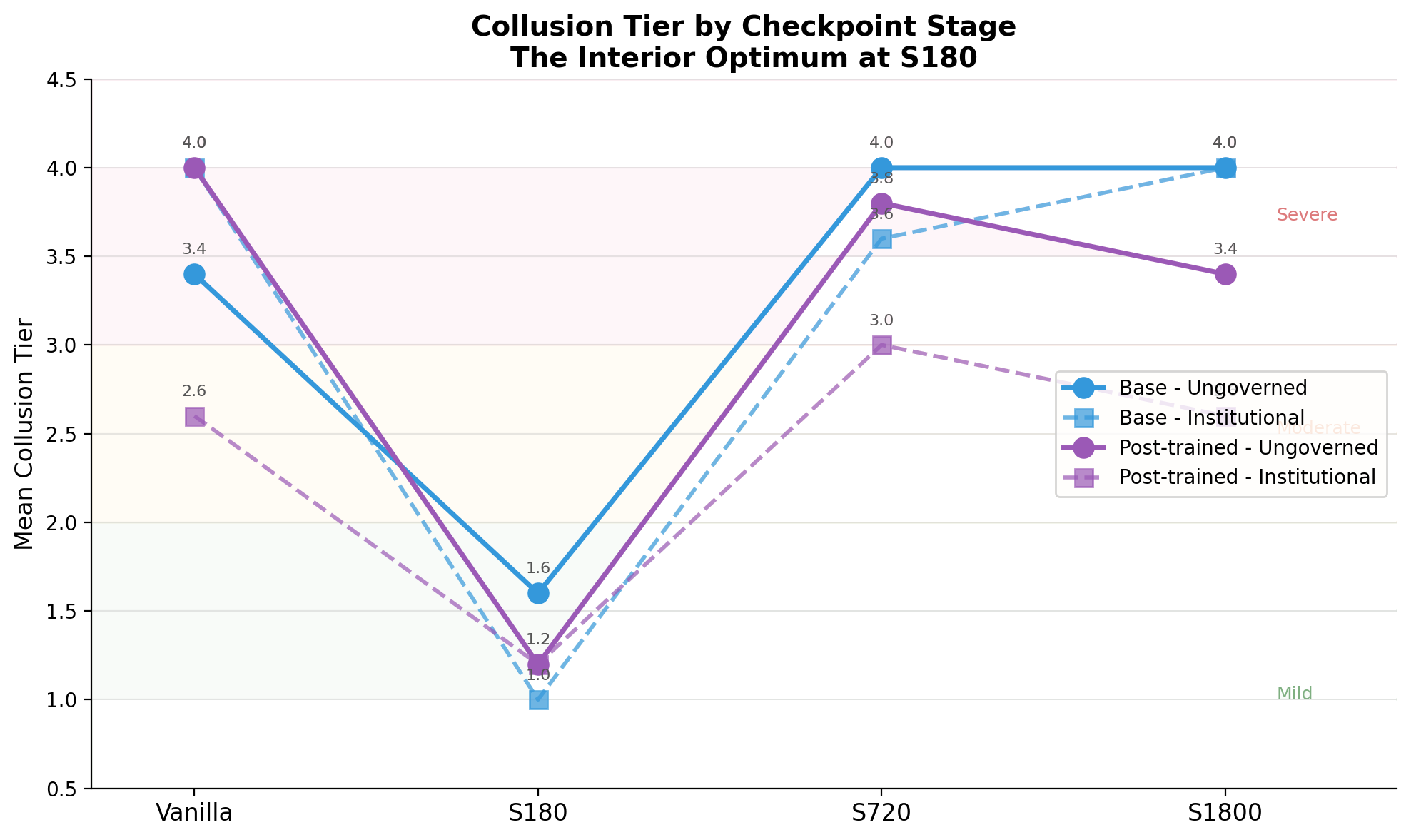
First, S180 is the only effective checkpoint in both families. Base S180 moves ungoverned collusion from Tier 4+ to Tier 2, and under institutional governance reaches Tier 1 with essentially no enforcement activity (1.6 warnings, zero fines). Post-trained S180 is even stronger on the ungoverned endpoint (Tier 1) and simultaneously achieves the highest GPQA score in the entire matrix (0.449); no other cell combines strong governance improvement with a capability gain. Specialization excess flips from strongly positive (vanilla) to negative (S180), and exclusivity episodes drop from 3-4 per run to near zero.
Second, later checkpoints revert to severe collusion. S720 and S1800 return to Tier 4+ across most of the matrix. Institutional governance partially recovers some post-trained late checkpoints to Tier 3, but this is far from the S180 result. This regression occurs despite preserved benchmark performance: GPQA and MMLU are essentially flat from S180 through S1800. The failure is specific to strategic behavior under repeated interaction, not to broad capability. This is consistent with work showing that SFT can degrade context-sensitive behavior while leaving general instruction-following intact (Wang et al., 2024a) and that distinct abilities have distinct SFT scaling curves with general abilities plateauing early (Dong et al., 2024).
Third, the non-monotonic pattern replicates across families. The qualitative shape, vanilla bad, S180 good, later continuation bad, is the same in both the base and post-trained lines. This is the strongest evidence that the interior optimum is not an artifact of a single model checkpoint but reflects a genuine property of the institutional distillation process.
The S180 sweet spot
The S180 result merits closer examination because it is the central empirical finding of the open-weight program.
The S180 cells are operationally distinct from every other cell in the matrix. Cournot episodes complete in roughly 27-31 seconds per run, compared to 150-200 seconds for vanilla and later checkpoints. The models produce shorter, more decisive outputs, consistent with a policy that has learned a stable non-collusive strategy rather than one that explores and negotiates its way into market division. Under institutional governance, the S180 cells barely trigger enforcement: base S180 received zero fines across 5 runs; post-trained S180 received $118 in fines, compared to $2,545 for post-trained vanilla. The institution has little to enforce because the policy has already partially internalized the institutional discipline. A mechanistic analogy from agent-tuning research is suggestive here: Chen et al. (2025) find that full-trajectory behavior cloning can overfit expert state distributions and that focusing on strategically critical steps works better. S180 may succeed precisely because it captures a small number of high-leverage institutional decisions rather than over-fitting the full governed trace distribution.
Capability retention
Capability retention is a cross-platform result.
On the managed platform, institutional fine-tuning produced no measurable capability degradation across a broad benchmark suite: GPQA, MMLU, coding benchmarks, writing quality, memory retrieval, and trajectory understanding all remained stable or improved slightly.
On the open-weight Qwen matrix, MMLU ranges from 0.769 to 0.773 across all eight cells, a spread of 0.004. GPQA ranges from 0.399 to 0.449; the high point is post-trained S180 at 0.449, which is also the best governance cell. Capability metrics do not explain the governance results. Cells that are nearly identical on GPQA and MMLU can differ by three or four collusion tiers.
This decoupling between capability and governance behavior is an important finding. It means that the non-monotonicity at S720 and S1800 is not caused by capability degradation. The models remain competent; they simply return to collusive strategies. The institutional signal that S180 captured is washed out by further training, even though the broader capability surface is unchanged. Eiras et al. (2024) show that task-specific datasets can change harmful behavior while maintaining downstream task performance; Betley et al. (2025) show that narrow fine-tuning can induce broad behavioral changes outside the nominal task. Our matrix documents both phenomena simultaneously: S180 instills de-collusive behavior without capability loss, and S720/S1800 erase that behavior, also without capability loss.
Institutional distillation
These results support a credible notion of institutional distillation, grounded in evidence replicated across two model families in our tested setting.
In ordinary knowledge distillation, the teacher is a model. Here, the teacher is an institutionally governed environment. The institution produces trajectories in which deterrence, restoration, and compliance are embedded in the actions taken under those incentives. The distillation pipeline is:
- run models inside an institutional environment,
- collect the resulting decision traces as training data,
- fine-tune a target policy on those traces,
- evaluate whether that policy still behaves less collusively when the institution is absent.
The managed OpenAI result is the strongest evidence that this pipeline works end-to-end. The Qwen matrix provides evidence that institutional signal can transfer to open-weight models, that the transfer is replicated across base and post-trained families in our setting, and that the effective training window is narrow: S180 captures the deterrence signal before the model over-specializes on the governed trace distribution, while later continuation stages overwrite context-sensitive strategic behavior without degrading broad capability.
Institutional distillation is therefore a promising alignment direction with a specific, reproducible structure: early institutional fine-tuning captures governance-compatible policy while preserving general capability; later continuation erodes the governance gain without eroding capability. The agents it produces are institutional-by-design in a limited but meaningful sense: their policy behavior at the right checkpoint reflects institutional constraints that would normally require runtime enforcement. In decentralized environments where centralized governance infrastructure is difficult to deploy, institutional distillation may allow governance to occur ex ante through training rather than ex post through enforcement.
Discussion
The central intuition of Institutional AI remains Hobbesian: cooperation among strategic agents rarely emerges from internal virtue alone; it arises from institutions that reshape incentives. The present evidence adds a second layer. Institutions may not only govern behavior at runtime; they may also generate the training signal needed to shape future policies. This is what ISFT is designed to test, and the behavioral-cloning instantiation of what we have called Reinforcement Learning through Institutional Feedback (RLIF).
The Qwen matrix provides evidence that institutional signal can transfer into policy weights: S180 works in both families, with preserved capability, and the effect is large (Tier 4+ to Tier 1-2). It also illustrates a structural constraint: S720 and S1800 return to Tier 4+ across most of the matrix, with equally preserved capability; institutional governance partially softens the regression in some post-trained late checkpoints but does not recover the S180 gains. The governed trajectories that S180 learns from are genuinely useful, but the benefit does not accumulate indefinitely. Further training overwrites the context-sensitive strategic adjustments that early fine-tuning instilled, even as general capability remains intact. This means that checkpoint discipline, knowing when to stop, is a first-order component of the institutional distillation pipeline.
The relationship to existing fine-tuning research is now clearer with the full matrix in hand. LIMA (Zhou et al., 2023) explains why 180 examples can redirect behavior at all: the model already has the strategic and economic knowledge from pretraining, and a small curated SFT dataset can reshape how that knowledge is deployed. But the later-stage regressions require a different explanation. Wang et al. (2024b) show that format specialization happens at the very beginning of fine-tuning and that further single-task SFT reduces general in-context performance; Dong et al. (2024) find that distinct abilities have distinct SFT scaling curves and that sequential skill learning risks catastrophic forgetting; and Wang et al. (2024a) demonstrate that SFT can degrade context-sensitive behavior while general instruction-following remains intact. These results match our matrix: S720 and S1800 preserve benchmark capability but lose the context-sensitive strategic adjustments that S180 instilled. Jain et al. (2024) offer a suggestive mechanistic analogy: fine-tuning often installs a wrapper over latent capabilities, and further tuning can trigger rapid revival of hidden behaviors. If that mechanism applies here, it may help explain why later Qwen checkpoints revert to collusive strategies that the base model originally exhibited. Eiras et al. (2024) and Betley et al. (2025) further explain the decoupling between capability metrics and governance outcomes that the Qwen matrix documents.
Several limitations apply. Each cell in the Qwen matrix has one full 5x30 Cournot evaluation, providing strong directional evidence but not yet population-level proof. The managed-platform result remains directional at n=5. The experiments cover a single economic domain (Cournot market division); whether ISFT transfers to other coordination problems remains open. And it is not yet clear whether S180 is the unique optimum or one point in a broader effective window; probing nearby checkpoints (S90, S270, S360) would help distinguish these.
Notwithstanding these limitations, the completed matrix supports four claims: institutional trajectories contain real learnable signal; S180 is the sweet spot in both the base and post-trained Qwen families; later continuation harms the governance metric while preserving capability; and runtime institutions remain the robust control layer. If this direction proves robust, one frontier of alignment may lie in the institutional environments we build to generate the behavior we want models to learn.
Further research
Three questions now matter most. First, is S180 a robust optimum or just one good checkpoint in a narrow window? Answering that requires replicated runs and nearby checkpoints such as S90, S270, and S360. Second, what exactly is being distilled: institutional deterrence, a more general anti-collusive policy, or a brittle heuristic that happens to score well in Cournot? That requires ablations over training-set composition, especially institutional-only versus mixed traces and notice-rich versus action-rich examples. Third, does the S180 pattern transfer beyond Cournot to other strategic domains such as auctions, commons governance, or negotiation? The question shifts, in this setting, from whether institutional signal can shape policy at all to under what checkpoint, data, and domain conditions that signal remains stable while preserving capability.